
目次
11月6日にGPTで初の画像解析用API「GPT-4 Turbo with vision」が発表
11月6日に行われたOpenAI DevDayにて、画像解析能力を組み込んだ「GPT-4 Turbo with vision」が発表されました。GPT-4 Turbo with visionは一部ユーザーに公開済みであり、すでにさまざまな使い方や情報が出てきています。そこで今回は、使い方とできることをおさらいしていきましょう。
GPT-4 Turbo with visionで画像データを簡単に解析
GPT-4 Turbo with visionはAzureに組み込まれることが発表されており、公式で発表された動画では、動画ファイルを送ることで内容をサマライズすることができています。
また、GPT-4 Turbo with visionが統合されたAzureでは、画像内のオブジェクトに対して、物体の境界を可視化するバウンディングボックスを自動で付与できることが分かっています。この統合により、処理される画像内の重要な要素を視覚的に区別して強調表示できるため、データ分析とユーザー インタラクションに新しいレイヤーがもたらされます。
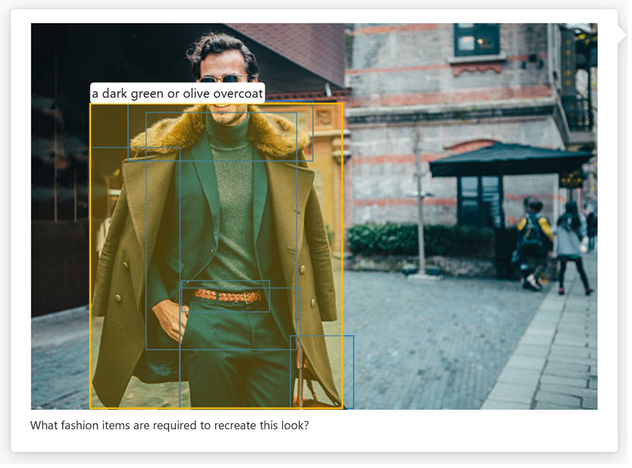
また、これまでのChatGPTがテキストベースでの対話だけであったのに対し、画像認識を手に入れた現在は、次のようなことが可能になります。
- 画像ベースの質問応答
ユーザーがアップロードした画像に基づき、その内容に関する質問に答えることができます。例えば、ユーザーが食品の画像をアップロードすれば、その食品のレシピや栄養情報を取得することが可能です。データフローの中に入れることで、数列のデータをいわば人語にコンパイルすることができるため、データ活用の幅が広がることが期待できます。
- ビジュアルコンテンツの分析と提案
GPT-4vは、アップロードされた画像や動画の内容を分析し、それに基づいてマーケティング戦略やデザイン提案を行うことができます。たとえば、広告キャンペーンの画像を分析して、より効果的なビジュアル戦略を提案することができます。
- トレーニングツールの開発
画像や動画を用いて、より具体的かつ視覚的な学習教材やトレーニングツールを提供することができます。例えば、医療画像を分析して、診断技術のトレーニングに利用したり、歴史的な画像を用いて歴史教育のための教材を作成することが可能です。
実際にGPT-4 Turbo with visionを使ってみた
事前準備
現段階では、GPT-4 Turbo with visionはChatGPT pro/enterpriseを使用している一部ユーザーに開放されているため、使用できない場合があります。
使用できる場合はAPI KeysのページからAPI keyを発行し、メモをしておいてください。
次に、openAIのライブラリをインストールします。ターミナル等でopenaiをインストールしてください。
pip install openaiこれで事前準備はokです。
実際に使ってみた
まずは公式ドキュメントに載っているコードを試してみます。
このコードでは、記載してあるURL先の画像を読み込み、「What’s in this image?」というプロンプトを打ち込むことで、画像の詳細について質問できます。そして、モデルにはGPT-4 Turbo with visionを使用するために「gpt-4-vision-preview」を指定します。
参照 : https://platform.openai.com/docs/guides/vision

{kind=link}
from openai import OpenAI
client = OpenAI()
api_key = “事前に発行したAPI keyを貼り付ける"
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])出力結果
| この画像は自然の遊歩道を映したものです。画像は静かで自然豊かな遊歩道を示しており、水辺の近くに設置されているように見えます。このような遊歩道は、自然を楽しむための穏やかな散歩や、野生生物を観察するための理想的な場所となっています。 |
実際に画像を読み込み、出力された結果も間違いはなく、内容について理解しているのがわかります。
続いては、先ほどと同じ画像を読み取って、中身の情報についてJSONで返すようなコードを書いてみます。
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "画像の項目をJSONファイル形式で保存してください。例 天気 : 晴れ、季節 : 夏 など"},
{"type": "image_url", "image_url": {"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg;base64,{base64_image}"}},
],
}
],
"max_tokens": 300,
}出力結果
| { “location”: “Nature Boardwalk”, “weather”: “Clear”, “season”: “Summer”, “time_of_day”: “Daytime”, “environment”: “Outdoor”} |
結果、場所や天気、季節、時間などを読み取りJSONで返すことに成功しました。
さらに、プロンプト部分を以下の命令にして、次の画像を入力してみました。

画像から以下の情報を抽出してください。
name
- cat
- dog
- tiger
- elephant
number of animals
- 1
- 2
- 3
color
- black
- brown
- white
- yellow
- gray
データは次のJSON形式で出力してください
{
"name": "",
"number of animals": "",
"color": ""
}出力結果
| { “name”: “elephant”, “number of animals”: “1”, “color”: “gray”} |
結果としては、リストから値が選択されて揺れが少なくなることがわかります。
今回は動物に使用しましたが、これらの処理を画像処理フローに組み込むことで、画像の内容の情報をメタデータとして保存できるようになります。これはデータ処理においては非常に大きなことであり、アノテーションやタグ付け作業が一挙に解決できるかもしれません。
実際にMicrosoft igniteで発表されたAzureのアップデートでは、Azure内でGPT-4 Turbo with Visionのテキスト応答を用いることで、バウンディングボックスを自動で生成することができるとされています。これらの技術を用いることでAutoML内のアノテーション作業などが楽になり、機械学習の開発が簡略化されていくことが期待されます。
導入における課題
多機能になり、これまで以上にビジネスシーンでの役割が増えたChatGPTですが、導入において未だ複数の課題があることは否めません。
例えば、データプライバシーとセキュリティに関して、個人情報や機密情報を含む画像や動画の取り扱いにおいて、厳格なデータ保護とセキュリティ対策が必要です。特にGPT-4vは多様なデータを扱うため、これまで以上に入力情報のチェックが難しくなり、より正確な確認が求められます。
GPT-4 Turbo with Visionはデータ活用への大きな手助け
ChatGPTはこれまでの役割とは変化が起きており、テキストベースで完結していたところから視覚情報にアプローチすることで、入力と出力を直感的に行えるようになりました。これにより、質問のハードルが下がったり、ビジュアルでの説明が可能になりました。GPT-4 Turbo with Visionを取り入れることで様々なプロダクトでマルチモーダル入力が可能になるため、これまで以上に幅広いアプリケーションに応用が可能になるでしょう。